Künstliche Intelligenz (KI)

Definition von künstlicher Intelligenz
Künstliche Intelligenz (KI) ist die Fähigkeit einer Maschine, kognitive Funktionen auszuführen, die dem menschlichen Verstand zugeordnet werden (Wahrnehmen – Denken – Lernen – Problemlösen).
Auf KI basierende Systeme analysieren ihre Umgebung und handeln autonom, um bestimmte Ziele zu erreichen. Das beinhaltet sowohl von Experten generiertes Regelwissen (regelbasierte KI), aber auch Wissen basierend auf Daten aus abgeleiteten statistischen Modellen (maschinelles Lernen/lernbasierte KI). Alle Ketten aus Wahrnehmen – Verstehen – Handeln, welche virtuell umgesetzt werden, verstehen wir als KI-Systeme. Dies beinhaltet einerseits reine Softwaresysteme, die Entscheidungen in virtuellen Umgebungen treffen, als auch Hardwaresysteme, wie Roboter.

Quelle: AIM AT 2030, www.bmvit.gv.at
KI-Systeme auf Basis von statistischen Modellen
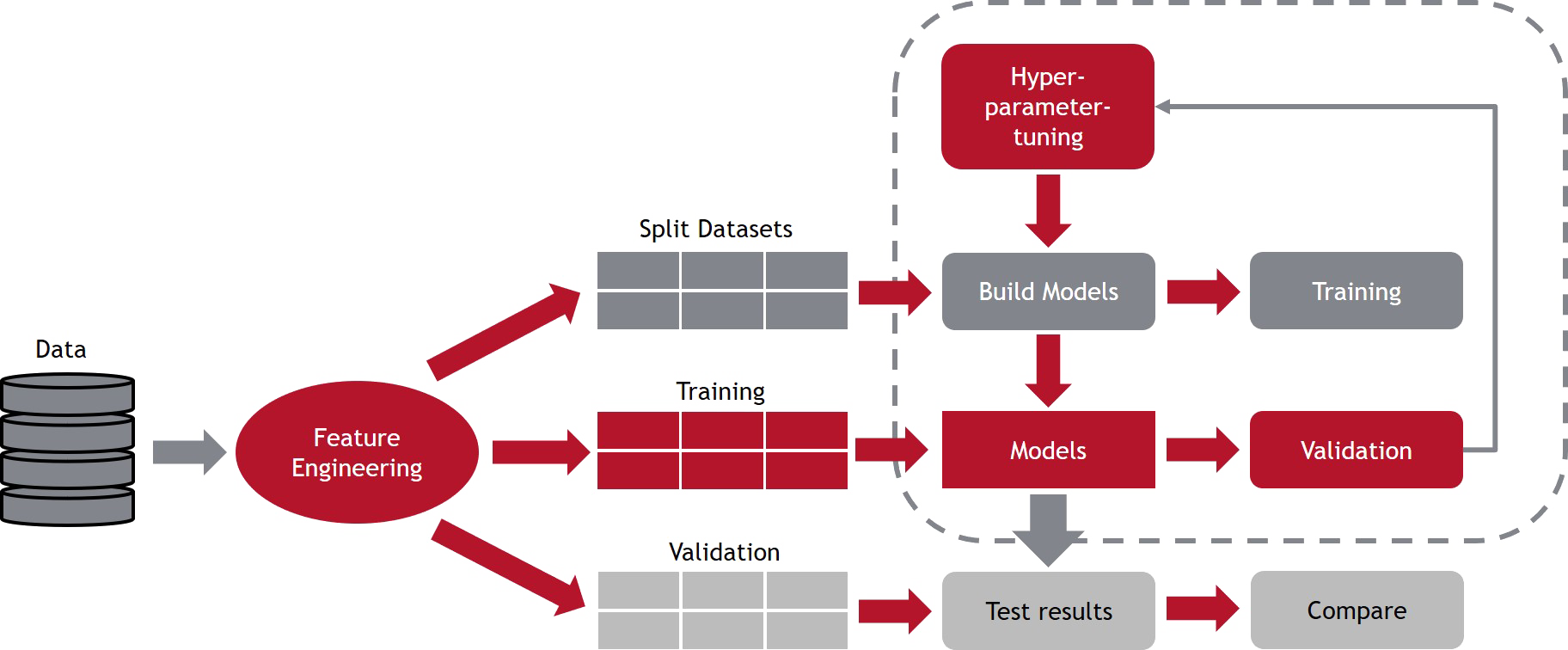
Das Anlernen von KI-Lösungen anhand von Daten nennt man „Supervised Learning“. Dazu benötigt man für die Zielgröße „gelabelte“ Daten. Jede Beobachtung muss mit einer richtigen Antwort gekennzeichnet werden. Der Algorithmus lernt was „richtig“ ist (daher „Supervised Learning“, also „überwachtes Lernen“), somit kann ein Vorhersagemodell erstellt werden.
Statistische Methoden für das Supervised Learning werden in Klassifikations- und Regressionsaufgaben unterschieden:
- Regression ist die Aufgabe für die Modellierung kontinuierlicher Zielvariablen. Die lineare Regression ist das einfachste Beispiel für ein Vorhersagemodell.
- Klassifizierung ist die Aufgabe für die Modellierung kategorialer Zielvariablen. Die binär logistische Regression sei hier als einfachstes Beispiel genannt.
Darüber hinaus gibt es eine Vielzahl an weiteren statistischen Methoden, die zur Modellierung herangezogen werden, wie z.B. Support Vector Machines, Naive Bayes oder neuronale Netze.
Um sicherzustellen, dass der trainierte Algorithmus die notwendige Vorhersagegenauigkeit aufweist, werden die zur Modellierung verwendeten Daten in einen Trainings- und Validierungsdatensatz aufgeteilt. Mit dem Trainingsdatensatz wird das Modell angelernt und anschließend am Validierungsdatensatz hinsichtlich der Vorhersagegenauigkeit getestet.
Besondere Beachtung muss beim Trainieren des Modells dem Hyperparametertuning gewidmet werden. Hyperparameter sind jene Parameter, die zur Steuerung des Trainingsalgorithmus verwendet werden, wie z.B. die Anzahl der künstlichen Neuronen oder versteckten Schichten in einem neuronalen Netz.
Künstliche Intelligenz erklärbar machen
Da je nach verwendeter Methode die Algorithmen beliebig kompliziert werden können (man denke beispielsweise an Deep Neural Networks mit zig Neuronen und versteckten Schichten), legen wir besonderen Fokus auf die Erklärbarkeit von KI-Lösungen. Dabei gilt der Grundsatz, dass das einfachste Modell zu präferieren ist. Zur besseren Interpretation des Einflusses von Features (Einflussfaktoren) auf die Zielgröße wird SHAP (SHapley Additive exPlanations ) angewandt. SHAP ist ein einheitlicher Ansatz, welcher jedem Feature einen sogenannten Shapley-Wert zuweist, der quantifiziert, wie dieses spezielle Feature die Ausgabe verändert hat.
KI Academy
Im Herbst 2019 haben wir unsere KI Academy ins Leben gerufen, um diesen speziellen Trainingsbedarf klar abzugrenzen und dem steigenden Bedarf gerecht zu werden. Mit unserer KI Academy werden Sie zum Spezialisten im Bereich KI!
Unser Trainingsangebot in diesem Bereich umfasst einerseits die jeweils 1-tägigen Basisschulungen bzw. Vertiefungsschulungen sowie die beiden Ausbildungen „Certified Citizen Data Scientist“ und „Certified Data Driven Problem Solving Training“, welche mit einer nach ISO17024 zertifizierten Prüfung zum Six Sigma Green Belt/Black Belt/Master Black Belt in der Vertiefung „data analytics“ abschließen.
Selbstverständlich bieten wir auch genau für Ihr Unternehmen maßgeschneiderte Lösungen und KI Trainings an! Gerne integrieren wir auch andere Teilbereiche unseres Trainingsangebots in Ihre KI Trainings.
Nähere Infos entnehmen Sie bitte unserem neuen Folder AI & DATA SCIENCE ACADEMY sowie unserer Fokusseite auf LinkedIn „AI – trustworthy and explainable„. Als Follower dieser Seite halten wir Sie über News in diesem Bereich auf dem Laufenden.