Data Mining, Machine Learning and AI

Challenges of large datasets
Industry 4.0, Internet of Things, and System of Systems are three buzzwords that are currently hotly debated. What these three terms entail is an ever-increasing interconnectedness of system elements and systems and thus immense amounts of data are generated. The analysis of these data mountains poses new challenges across all sectors and divisions and requires special statistical methods. Companies which use this existing information can generate competitive advantages and ensure constant growth in the future as well.
Big Data, Data Mining, Predictive Analytics
The term big data refers to data volumes that are too large to be evaluated using manual and classical methods of data processing. Big data is often the umbrella term for digital technologies that are technically blamed for the new era of digital communication and processing and socially responsible for social change.
By data mining analytics we understand the extraction of knowledge from large amounts of data that is unknown but potentially useful. The aim is to recognize cross-connections, patterns and trends with the systematic application of statistical methods.
Predictive analytics refers to calculated mathematical models based on collected data, which allow systems to make forecasts. In predictive analytics, mathematical models are trained on a dataset and then validated against an unknown dataset. The aim is that this algorithm achieves the best possible adaptation to the task to be performed, in order to be able to predict events. Predictive analytics is mainly used in machine learning. The best-known predictive techniques are neural networks and ensemble models.
Machine Learning and artificial intelligence (AI)
Machine learning is about teaching computers how to learn from data to make decisions and predictions based on it. The necessary knowledge is generated from experience (with the help of learning data), without the computer being explicitly programmed. As in the case of data mining or predictive analytics, the art is not simply to study learning data by heart, but recognizing underlying patterns. This is the only way to avoid “overfitting” and to ensure that the system can also evaluate unknown data.
One can also see machine learning as part of artificial intelligence. The term artificial intelligence stands for the efforts to reproduce human-like decision-making structures in a non-ambiguous environment, i.e. to realize an agent so that he can independently work on problems. In most cases (but not always) the ability to generate knowledge from experience (= machine learning) is necessary.
The topic is closely related to data mining and predictive analytics. However, while data mining is applied to a defined dataset by a human in a specific situation, the goal of AI and machine learning is to program intelligent agents. However, the algorithms and methods are largely identical.
Business Intelligence
The term Business Intelligence, abbreviation BI, became popular from the beginning to the mid-1990s and refers to procedures and processes for the systematic analysis (collection, evaluation and presentation) of data in electronic form. The goal is to gain insights that enable better operational or strategic decisions in terms of corporate goals.
This is done with the help of analytical concepts and appropriate software. Now, a company needs systems for collecting and managing data such as Apache Hadoop. In addition, software for analyzing this data is necessary. The best known software tools for data mining analytics are JMP, Rapid Miner and R.
The CRISP-DM Process Model as a standardized data mining approach
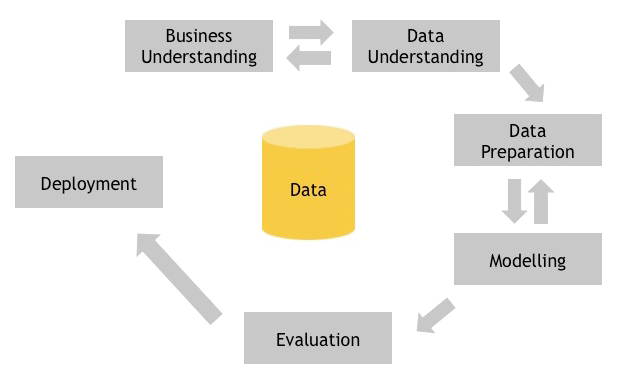
The analytical concept CRISP-DM stands for Cross-Industry Standard Process for Data Mining and is a process model that corresponds to the usual procedure of a data mining expert or data scientist.
The first phase is about business understanding, which is to understand and describe the project goal from a business perspective. Here it is important that the customer does describe the requirements not the Data Mining Analyst. The purpose of the Data Understanding Phase is to understand the initial data collected and to assess its quality. The Data Preparation Phase prepares the final dataset, which is used during the Modeling Phase to determine the mathematical model with the best fit. Before handing over the results to the customer in the Deployment Phase, they must be checked for suitability in the application during the Evaluation Phase.
Method training on data mining, machine learning and AI
Our application-based methodology trainings (such as the Data Mining Analyst training) provide an overview of the most common data mining, predictive analytics, machine learning, and artificial intelligence tools and methods. We are guided by the CRISP-DM as well as other procedural models in the field of machine learning. We teach statistical methods such as cluster analysis, PCA, CART and neural networks. With the help of practical case studies, the individual subject areas are conveyed in an exciting and interactive way. Discover and learn from us the tools for data mining, machine learning and AI and become an expert for the modeling of large databases.